众所周知,Hadoop的存储组件有已经存活了十二年之久的HDFS,问世三年而用户寥寥的KUDU,以及来势凶猛的新晋网红Ozone。
KUDU虽然有和HDFS一样的水平扩展能力以及近似HBase的高效随机读写能力,但受限于其功能局限性以及和其他软件之间的兼容能力不强,因此目前主要作为存放"实时更新的,用来做快速分析的结构化数据"的载体,这部分数据量不会太大,比起HDFS中的数据应该会小的多。
Ozone到目前刚刚推出了alpha 0.4.1版本,离正式release还有一段路要走,所以短期内也只有小范围的试用需求。
说到底,目前的存储规划还是要以HDFS为主。而对于HDFS,这里有几个问题考量:
● HDFS容量
● 数据压缩
● 硬件选择
HDFS的容量
HDFS设计初衷是以多副本机制解决硬件的不可靠性,从而在节约硬件成本的情况下尽量提升数据的可用性与读写效率。HDFS通常默认配置为3副本,结合HDFS的机架感知特性,3个副本通常按照如下分布:
● 将第一副本写到离数据输入client最近的同一rack数据节点上,如输入client与集群数据节点分布在不同的机架上,则随机写入一个不太繁忙的数据节点。
● 将第二副本写入与第一副本不在同一rack的数据节点上。
● 将第三副本写入与第二副本同一rack的不同数据节点上。
在几年前大数据产业发展伊始,企业中的数据量都还是”数据库量级”的时候,数据库软件和专用存储都非常昂贵,这样做的确是最佳实践,既降低了软硬件的成本,还提高了数据的可用性。然而技术发展日新月异,在企业的大数据发展终于进入”大数据量级”的时候,即便是普通廉价的工业磁盘也因为集群过大,数量太多产生了经济方面的压力。
多副本机制是否有必要,是不是造成了存储资源的浪费?
Hadoop 3.X实现了EC码(纠删码)机制,来减少数据存储副本,提升数据的可用性。最简单的EC码是XOR编码(异或操作码),它的原理如下:
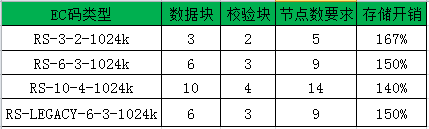
RS码策略存储开销
可以看出,使用了EC码(无论是XOR码还是RS码)以后,存储的开销都从之前的300%下降到了150%左右,但是不是说EC纠删码代替原来的多副本机制就是更好的解决方案?或者说考虑使用磁盘阵列(RAID)的方式来提高数据可用性操作性更强?毕竟RAID方式也是使用了EC纠删码的原理(RAID5实现了XOR的机制允许坏掉一个副本,RAID6则实现了RS的机制允许坏掉2个副本)。
事情没有这么简单,多副本机制与EC纠删码码机制相比,有以下特点:
多副本与EC码
可以看出,EC纠删码虽然大大提升了磁盘利用率,但是其在数据恢复方面的表现是不太理想的,因为EC纠删码的加密解密过程大大依赖于CPU的能力,而数据恢复过程中,又需要网络传输大量的数据。
在同一个集群中,同一份数据要么配置EC纠删码机制,要么配置多副本机制,两者是互斥的。基于这么一个前提,有benchmark测试表明,在未发生数据故障时,配置了EC纠删码和多副本机制的HDFS读写效率基本一致,但在发生了数据恢复时,多副本机制的HDFS读写效率要比EC码机制的读写效率快3-4倍。在数据量超大,CPU配置不高以及网络带宽有限的集群环境里,这也是相对致命的问题。
要不要使用磁盘阵列(RAID)的方式?
其实配置磁盘阵列与配置HDFS纠删码实现原理是一样的,但是磁盘阵列只在单个节点生效,HDFS纠删码则针对整个集群生效。换句话说,即便配置了磁盘阵列,但是单个节点的服务器如果由于磁盘以外的其他原因故障了,那数据就丢失了,这个风险很大,因此使用HDFS纠删码要比单纯使用磁盘阵列安全的多。
怎么选择使用多副本机制还是EC纠删码?
通常建议热数据较多,业务密集型的集群还是按照3副本机制进行配置容量,而冷数据较多,以存放备份归档数据为主的集群可考虑以EC纠删码的方式来进行配置容量,但是磁盘总容量不应小于实际数据的大小的2倍。另外需要注意的是,使用EC纠删码只能在Hadoop 3.X以上的版本进行。





